Fichier CSV d’ontologie et des regex
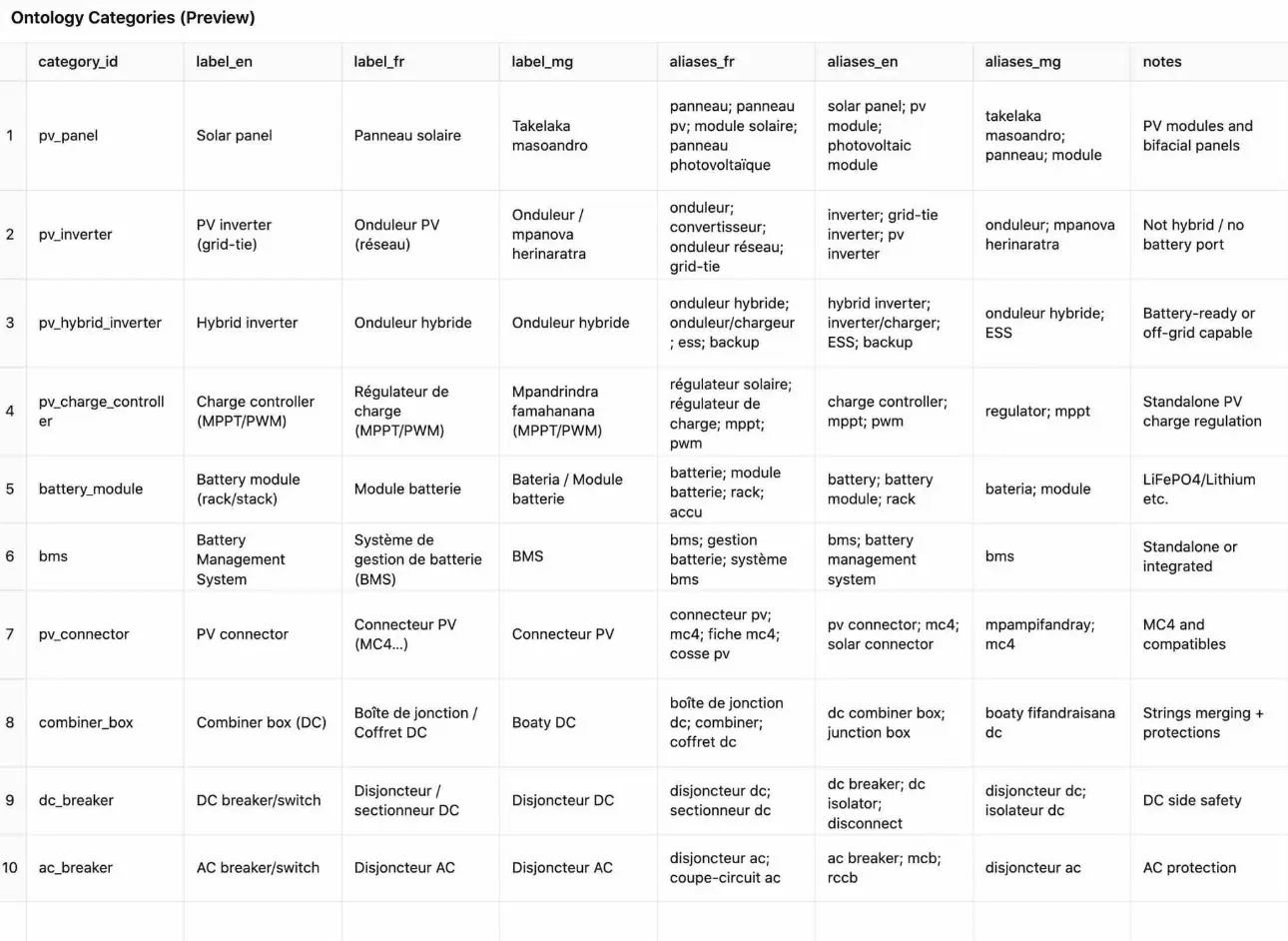
et
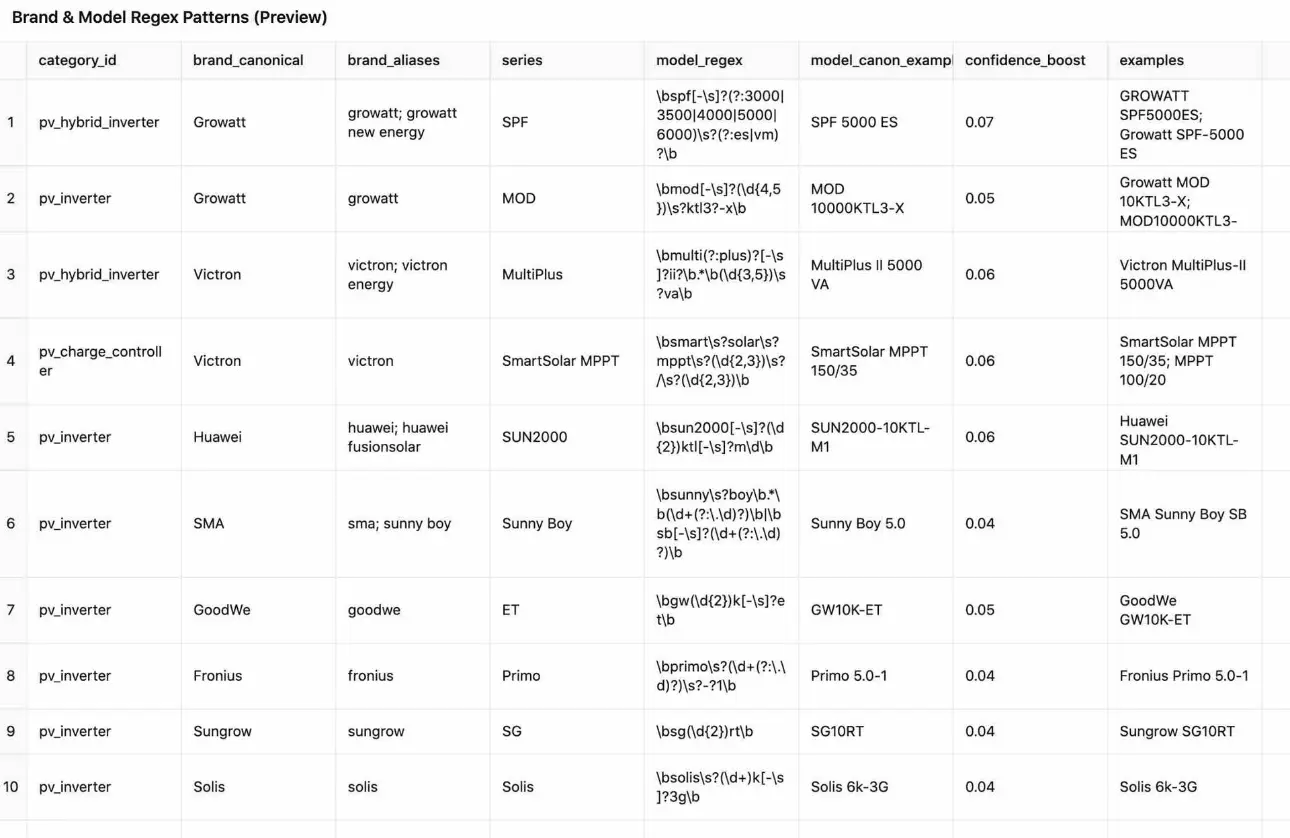
et
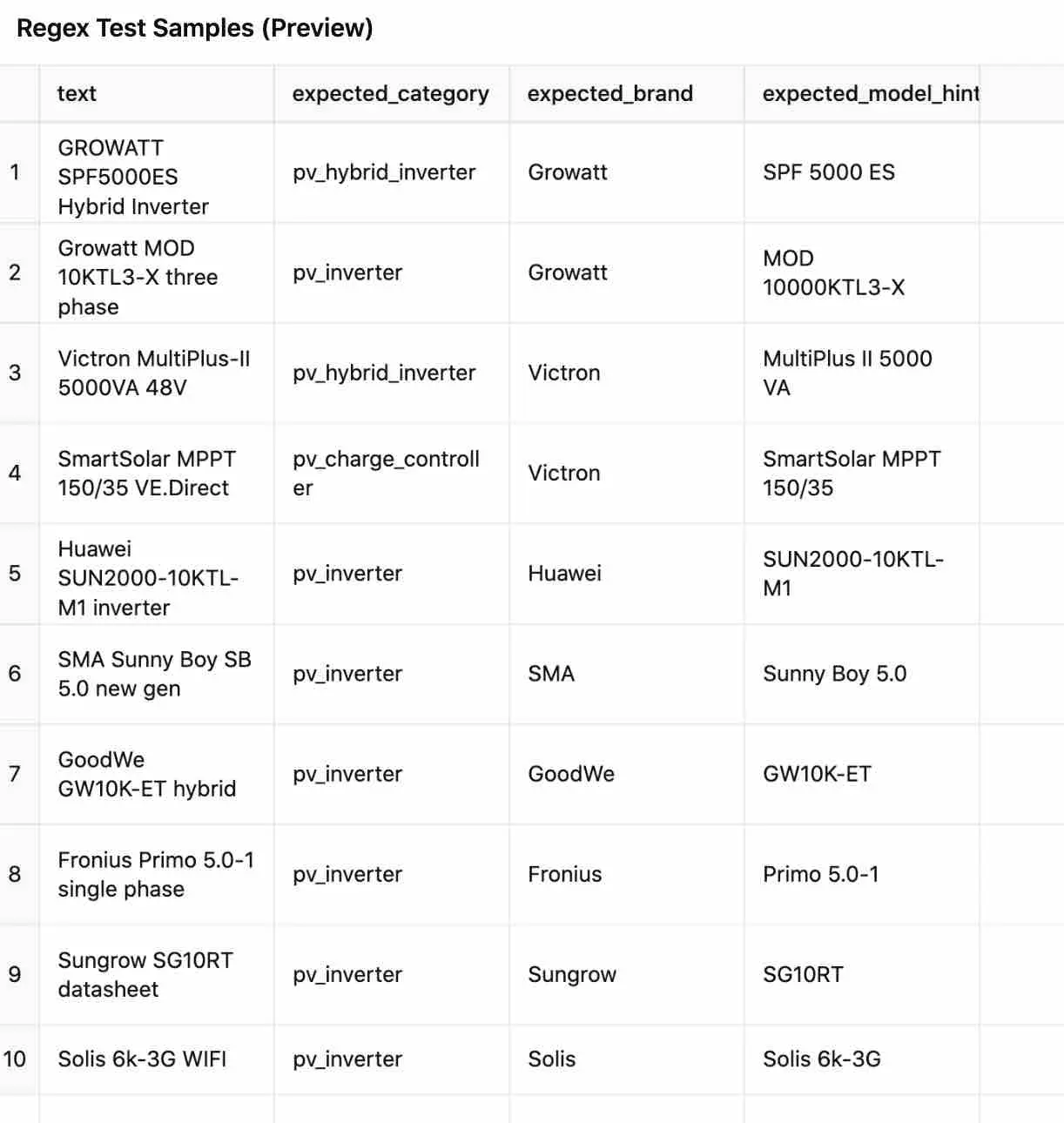
Parfait — j’ai généré trois fichiers CSV prêts à l’emploi :
- ontology_categories.csv — Catégories + alias FR/MG/EN (vocabulaire contrôlé).
- brand_model_patterns.csv — Marques canoniques + alias + regex modèles (+ exemples).
- regex_test_samples.csv — Jeux d’exemples pour valider vos regex dans le pipeline.
Utilisation express (pseudo-code)
- Chargement des CSV → normalisation → extraction :
# 1) charger CSV import pandas as pd, re, unicodedata, json cats = pd.read_csv("ontology_categories.csv") pats = pd.read_csv("brand_model_patterns.csv") def norm(s): if not isinstance(s,str): return "" s = unicodedata.normalize("NFKD", s).encode("ascii","ignore").decode("ascii") return s.lower() def match_brand(text): t = norm(text) for _,row in pats.iterrows(): for a in str(row.brand_aliases).split(";"): if a.strip() and a.strip() in t: return row.brand_canonical return None def match_model(text, brand_hint=None): t = norm(text) for _,row in pats.iterrows(): if brand_hint and row.brand_canonical != brand_hint: continue rgx = re.compile(row.model_regex, flags=re.I) if rgx.search(t): return { "category": row.category_id, "brand": row.brand_canonical, "model_regex": row.model_regex, "series": row.series, "model_example": row.model_canon_example, "confidence_boost": row.confidence_boost } return None
Les grandes histoires ont une personnalité. Envisagez de raconter une belle histoire qui donne de la personnalité. Écrire une histoire avec de la personnalité pour des clients potentiels aidera à établir un lien relationnel. Cela se traduit par de petites spécificités comme le choix des mots ou des phrases. Écrivez de votre point de vue, pas de l'expérience de quelqu'un d'autre.
Les grandes histoires sont pour tout le monde, même lorsqu'elles ne sont écrites que pour une seule personne. Si vous essayez d'écrire en pensant à un public large et général, votre histoire sonnera fausse et manquera d'émotion. Personne ne sera intéressé. Ecrire pour une personne en particulier signifie que si c'est authentique pour l'un, c'est authentique pour le reste.